Understanding when to cache your APIs

What is caching?
Caching is a mechanism to temporarily hold on to data returned over the network to end-user devices. There are multiple ways to implement caching, out of which the principal divisions are: client-side and server-side.
Client-side caching
This is a procedure used to cache data responses from servers on the end-user’s devices. This can generally be configured into the REST API clients that are used to fetch API responses. Caching rules are configured and built into the REST API clients themselves, so the responsibility to cache and invalidate the cache rests totally on the frontend application. This method of caching is quite painless if you’re starting out on caching for some backend platforms where you’re not too bothered about maintaining the software at scale. In fact, you’ll mostly see developers prioritising using client-side caching when starting out on small/hobby projects or at small companies (mainly bootstrapping companies).
Server-side caching
Caching methods deployed on your server are commonly known as server-side caching techniques. This means clients don't need to cache API responses on their end. Without a cache, an API user would make a round trip through all the functions and middlewares attached to an API controller and ultimately return the response of the controller. With caching enabled, the round-trip would be intercepted and the response stored by a cache would be returned instead, thus reducing the API latency.
Cache Hit Ratio
When a cache encounters a request by a user for the first time, it checks to determine if the key for this certain request exists in it's database. If it does, this is termed as a cache hit. Otherwise, it is a cache miss. The cache hit ratio is defined as:
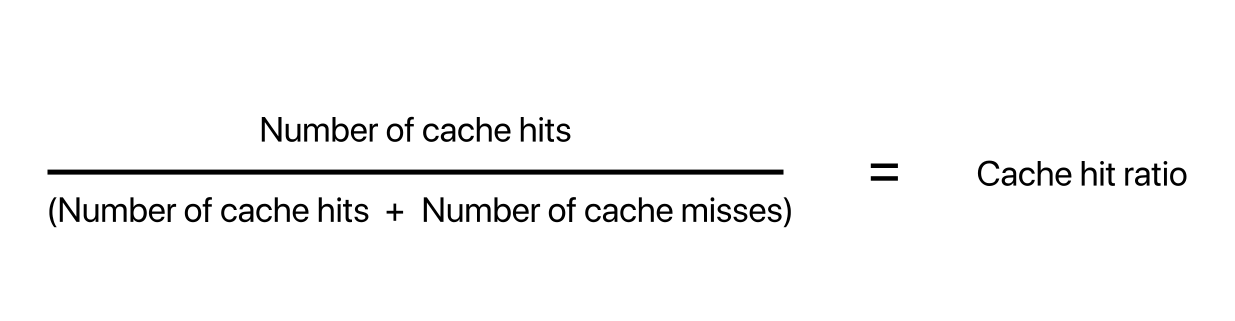
This hit ratio is crucial for determining the efficiency of the cache server or caching logic, and is one of the most important factors you should consider when deploying a cache in front of your backend stack.
When should you cache your APIs?
Now let’s assume you’re a software engineer currently managing the backend of a medium-scale company. The average load of users isn’t too high, perhaps 7000-8000 users daily (in the current age of a software-driven world, we can agree that this scale is somewhat of medium or medium-large type).
Given that you’re a backend engineer, chances are you’ve already faced these scenarios or at least are aware of some of the keywords in the following points:
- Request has timed out after 5000 ms
- Connection timed out, maxContentLength size of -1 exceeded
- Client exceeds API rate limiting quota (Error code 429)
These are some of the markers that indicate it’s time to start using caching techniques. Caching reduces load on the main API servers by diverting requests to a cache storage.
Today because of the importance of benefits caching brings to a software platform, there are many software implementations of cache database available, most of which are open-source and easy to deploy. The popular ones are Redis, Memcached, Varnish, etc. Popular cloud service providers like AWS, GCP, Azure, etc. provide their own dedicated caching services. However if you plan to use them, make sure to configure the storage & tiering options carefully, or you might end up racking up a huge bill.
Caching is a brilliant technique to reduce server load but we often fail to recognise where and when it is needed. Let’s look at a few cases where it makes the most sense to use caching (server-side).
Read-intensive data endpoints
API endpoints that are read-intensive benefit the most from having a cache layer. Imagine that you want to fetch the details of a user profile in your social media app. Generally, API endpoints that fetch user information do not return data that keep varying within seconds. Use caching on this type of API endpoints.
Cache expiry manipulation
Caching can be done variably with respect to expiry duration. Some endpoint return data that is expected to change over short durations i.e. a few seconds, while others may return data that does not change in hours or even days. Analysing the API stats via logging, metric aggregation and the underlying data type will give you an idea of what the expiry of cache on different endpoints should be.
Cache as a request idempotence guarantor
API request idempotence is important for endpoints that handle interactions that should not be repeated accidentally. A good example is an API endpoint that handles payment transactions; you certainly don’t want to pay twice for a single order. And while having separate middlewares for handling API idempotence is great, a cache layer can also help with the same objective. Simply set the cache key of the request equal to the idempotence key, you’ll be good to go! Although using caching on POST/PATCH/PUT/DELETE routes seems like an anti-pattern, I wouldn’t complain if it simplifies certain tasks.
Database caching
Remember that if you’re working in a resource-constrained environment or in one where you want to cut costs down to the minimum value possible, using in-built database caching can work as a great alternative. Of course, it requires working with the API of the database ORM that you’ve used in your project.
Reducing metered third-party API calls
Your APIs can sometimes reference data from third-party APIs. Most likely than not, these third party APIs will be metered in costs. Caching the data of these metered APIs will significantly help in controlling the costs and the latency of calling the external services.
Distributed applications
Many distributed backend use-cases can benefit from having a warmed up cache for certain data in order to lower API response times. Let’s consider an app's chat system. For each conversation you have in the app, you’d store a copy of the N most recent messages in the cache so that you don’t have to query the primary database on every user entry into the chat window. The system benefits largely if the caching action is performed on every new message received as it bypasses the need to fetch messages from the persistence layer frequently. This helps reduce the session load on a database, which is awesome!
Cache key generation
When it comes to constructing your cache keys, try to get creative with its generator functions. You should avoid including all your headers, query and path parameters, and only include those that are most likely to change when making requests. This is due to the fact that a single API request on the same endpoint can return different data based on what parameters were passed along with the request.
Cache servers as rate limiters
Cache storages can be used as API rate limiters. In cases where you'd like to control how many requests your backend can process in a single interval, generally per second (/s), a cache store can track the number of endpoint requests against a user token or user ID, and restrict them from accessing that endpoint till the timer resets. It is important to mention that the frontend should implement exponential backoff policy for API requests, otherwise the server load on the cache storage tends to increase rapidly.
Conclusion
Caching is a very interesting subject, one which can serve a bunch of other useful scenarios (like the ones we've seen above) based on the same theoretical principals of caching requests. While it can improve the system performance of backends, it is worthwhile to note that it can produce erratic data towards end-users if the configuration isn't set correctly. Cache invalidation must be done correctly and manual invalidations may also be employed as the use-cases require, in order to ensure a seamless experience for the end-users.
Comments
(0)